
![]()
[Jun 04, 2026] Fully Updated Dumps PDF - Latest DP-700 Exam Questions and Answers
100% Free DP-700 Exam Dumps to Pass Exam Easily from Prep4sures
Microsoft DP-700 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
NEW QUESTION # 67
You need to troubleshoot the ad-hoc query issue.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.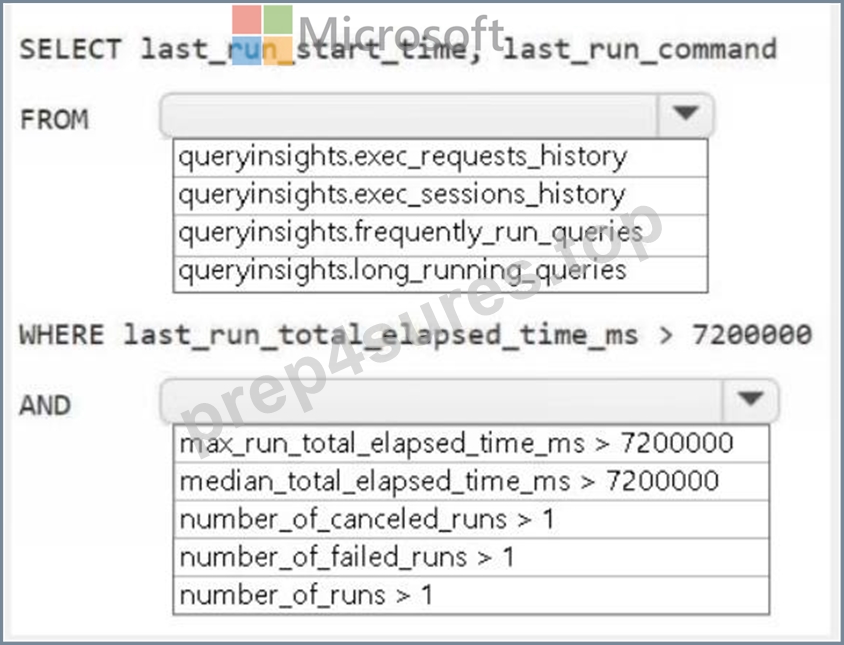
Answer:
Explanation: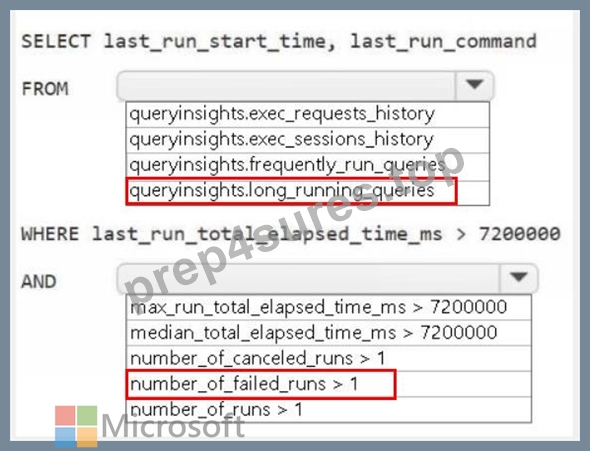
NEW QUESTION # 68
You have a Fabric workspace named Workspace1 that contains a notebook named Notebook1.
In Workspace1, you create a new notebook named Notebook2.
You need to ensure that you can attach Notebook2 to the same Apache Spark session as Notebook1.
What should you do?
- A. Increase the number of executors.
- B. Change the runtime version.
- C. Enable dynamic allocation for the Spark pool.
- D. Enable high concurrency for notebooks.
Answer: D
Explanation:
To ensure that Notebook2 can attach to the same Apache Spark session as Notebook1, you need to enable high concurrency for notebooks. High concurrency allows multiple notebooks to share a Spark session, enabling them to run within the same Spark context and thus share resources like cached data, session state, and compute capabilities. This is particularly useful when you need notebooks to run in sequence or together while leveraging shared resources.
NEW QUESTION # 69
You need to schedule the population of the medallion layers to meet the technical requirements.
What should you do?
- A. Schedule multiple data pipelines.
- B. Schedule an Apache Spark job.
- C. Schedule a notebook.
- D. Schedule a data pipeline that calls other data pipelines.
Answer: D
Explanation:
The technical requirements specify that:
Why Use a Data Pipeline That Calls Other Data Pipelines?
- Sequential execution of child pipelines.
- Error handling to send email notifications upon failures.
- Parallel execution of tasks where possible (e.g., simultaneous imports into the bronze layer).
NEW QUESTION # 70
You plan to process the following three datasets by using Fabric:
* Dataset1: This dataset will be added to Fabric and will have a unique primary key between the source and the destination. The unique primary key will be an integer and will start from 1 and have an increment of 1.
* Dataset2: This dataset contains semi-structured data that uses bulk data transfer. The dataset must be handled in one process between the source and the destination. The data transformation process will include the use of custom visuals to understand and work with the dataset in development mode.
* Dataset3. This dataset is in a takehouse. The data will be bulk loaded. The data transformation process will include row-based windowing functions during the loading process.
You need to identify which type of item to use for the datasets. The solution must minimize development effort and use built-in functionality, when possible. What should you identify for each dataset? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: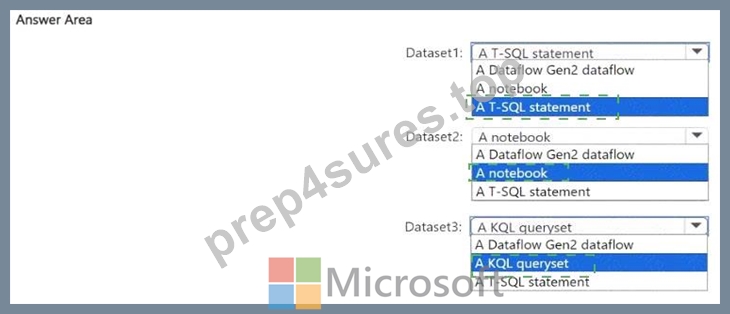
Explanation:
NEW QUESTION # 71
You have a Fabric notebook named Notebook1 that has been executing successfully for the last week.
During the last run, Notebook1executed nine jobs.
You need to view the jobs in a timeline chart.
What should you use?
- A. Monitoring hub
- B. the run series from the details of the application run
- C. Spark History Server
- D. the job history from the application run
- E. Real-Time hub
Answer: B
Explanation:
The run series from the details of the application run is the most detailed and relevant feature for visualizing job execution in a timeline format, making it the correct choice for this scenario. It provides an intuitive way to analyze job execution patterns and improve the efficiency of the notebook.
NEW QUESTION # 72
You have a Fabric workspace that contains a lakehouse named Lakehousel.
You plan to create a data pipeline named Pipeline! to ingest data into Lakehousel. You will use a parameter named paraml to pass an external value into Pipeline1!. The paraml parameter has a data type of int You need to ensure that the pipeline expression returns param1 as an int value.
How should you specify the parameter value?
- A. "@{pipeline().parameters.[paraml]}"
- B. "@{pipeline().parameters.paraml}"
- C. "@{pipeline().parameters.paraml}-
- D. "@pipeline(). parameters. paraml"
Answer: B
NEW QUESTION # 73
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a KQL database that contains two tables named Stream and Reference. Stream contains streaming data in the following format.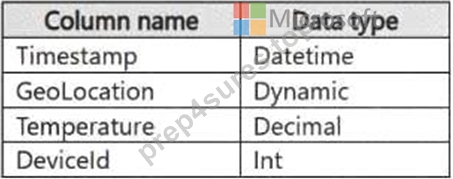
Reference contains reference data in the following format.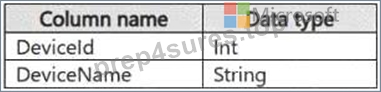
Both tables contain millions of rows.
You have the following KQL queryset.
You need to reduce how long it takes to run the KQL queryset.
Solution: You change the join type to kind=outer.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
An outer join will include unmatched rows from both tables, increasing the dataset size and processing time.
It does not improve query performance.
NEW QUESTION # 74
You have a Fabric workspace that contains a warehouse named Warehouse1. Data is loaded daily into Warehouse1 by using data pipelines and stored procedures.
You discover that the daily data load takes longer than expected.
You need to monitor Warehouse1 to identify the names of users that are actively running queries.
Which view should you use?
- A. queryinsights.frequently_run_queries
- B. sys.dm_exec_connections
- C. sys.dm_exec_requests
- D. sys.dm_exec_sessions
- E. queryinsights.long_running_queries
Answer: D
Explanation:
sys.dm_exec_sessions provides real-time information about all active sessions, including the user, session ID, and status of the session. You can filter on session status to see users actively running queries.
NEW QUESTION # 75
You have a table in a Fabric lakehouse that contains the following data.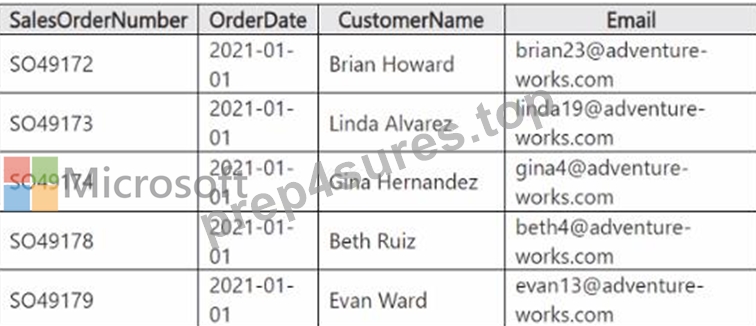
You have a notebook that contains the following code segment.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
NEW QUESTION # 76
You have a Fabric warehouse named DW1. DW1 contains a table that stores sales data and is used by multiple sales representatives.
You plan to implement row-level security (RLS).
You need to ensure that the sales representatives can see only their respective data.
Which warehouse object do you require to implement RLS?
- A. ISTORED PROCEDURE
- B. CONSTRAINT
- C. FUNCTION
- D. SCHEMA
Answer: C
Explanation:
To implement Row-Level Security (RLS) in a Fabric warehouse, you need to use a function that defines the security logic for filtering the rows of data based on the user's identity or role. This function can be used in conjunction with a security policy to control access to specific rows in a table.
In the case of sales representatives, the function would define the filtering criteria (e.g., based on a column such as SalesRepID or SalesRepName), ensuring that each representative can only see their respective data.
NEW QUESTION # 77
You have a Fabric workspace named Workspace1 that contains an Apache Spark job definition named Job1.
You have an Azure SQL database named Source1 that has public internet access disabled.
You need to ensure that Job1 can access the data in Source1.
What should you create?
- A. an integration runtime
- B. a data management gateway
- C. a managed private endpoint
- D. an on-premises data gateway
Answer: C
Explanation:
To allow Job1 in Workspace1 to access an Azure SQL database (Source1) with public internet access disabled, you need to create a managed private endpoint. A managed private endpoint is a secure, private connection that enables services like Fabric (or other Azure services) to access resources such as databases, storage accounts, or other services within a virtual network (VNet) without requiring public internet access.
This approach maintains the security and integrity of your data while enabling access to the Azure SQL database.
NEW QUESTION # 78
Your company has a sales department that uses two Fabric workspaces named Workspace1 and Workspace2.
The company decides to implement a domain strategy to organize the workspaces.
You need to ensure that a user can perform the following tasks:
Create a new domain for the sales department.
Create two subdomains: one for the east region and one for the west region.
Assign Workspace1 to the east region subdomain.
Assign Workspace2 to the west region subdomain.
The solution must follow the principle of least privilege.
Which role should you assign to the user?
- A. domain admin
- B. workspace Admin
- C. Fabric admin
- D. domain contributor
Answer: A
Explanation:
To implement a domain strategy and manage subdomains within Fabric, the domain admin role is the appropriate role for the user. A domain admin has the permissions necessary to:
Create a new domain (for the sales department).
Create subdomains (for the east and west regions).
Assign workspaces (such as Workspace1 and Workspace2) to the appropriate subdomains.
The domain admin role allows for managing the structure and organization of workspaces in the context of domains and subdomains while maintaining the principle of least privilege by limiting the user's access to managing the domain structure specifically.
NEW QUESTION # 79
You have a Fabric workspace named Workspace1 that contains the items shown in the following table.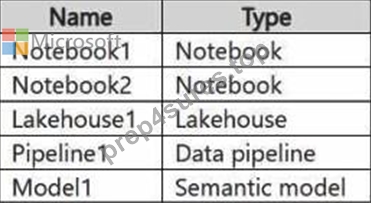
For Model1, the Keep your Direct Lake data up to date option is disabled.
You need to configure the execution of the items to meet the following requirements:
How should you orchestrate each item? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.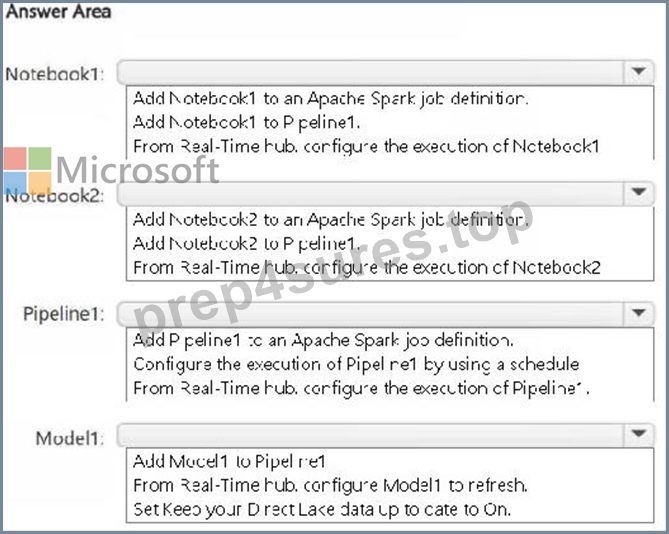
Answer:
Explanation: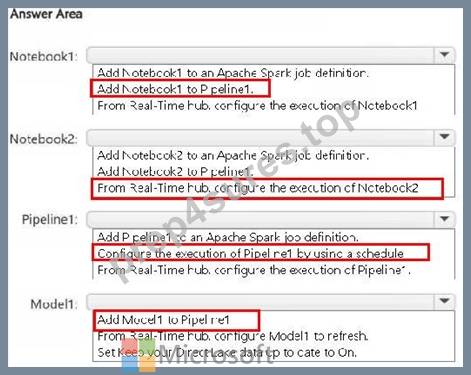
NEW QUESTION # 80
You have an Azure key vault named KeyVaultl that contains secrets.
You have a Fabric workspace named Workspace-!. Workspace! contains a notebook named Notebookl that performs the following tasks:
* Loads stage data to the target tables in a lakehouse
* Triggers the refresh of a semantic model
You plan to add functionality to Notebookl that will use the Fabric API to monitor the semantic model refreshes. You need to retrieve the registered application ID and secret from KeyVaultl to generate the authentication token.
Solution: You use the following code segment:
Use notebookutils.credentials.getSecret and specify the key vault URL and key vault secret. Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION # 81
You have a Fabric workspace named Workspace1_DEV that contains the following items:
You create a deployment pipeline named Pipeline1 to move items from Workspace1_DEV to a new workspace named Workspace1_TEST.
You deploy all the items from Workspace1_DEV to Workspace1_TEST.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
NEW QUESTION # 82
......
Free DP-700 Exam Questions DP-700 Actual Free Exam Questions: https://realdumps.prep4sures.top/DP-700-real-sheets.html